


Overview
Remember the different stages of a project’s pipeline? Let’s suppose we’re in the process of preparing our data set for analysis. For example:
- You wish to convert three raw data sets from Excel to CSV files.
- You want to merge these three CSV files and apply some cleaning steps.
- Finally, you want to save the final data set, so that it can be used in other stages of your project pipeline (e.g., such as the analysis).
This workflow for your specific pipeline can be visualized as follows:
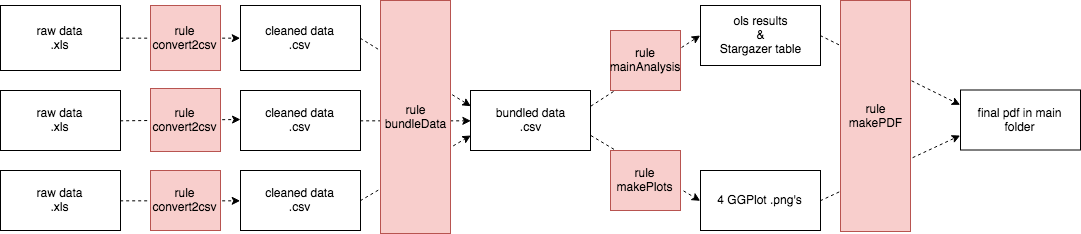
Using so-called “build tools” such as make, we can specify:
- what code runs and when, and
- what inputs (e.g., data, parameters) a given source code file needs to run.
Specifically, make introduces “recipes” that are used to tell make how to
build certain targets, using a set of source files and execution command(s).
- A target refers to what needs to be built (e.g., a file),
- source(s) specify what is required to execute the build, and
- the execution command specifies how to execute the build.
In make code, this becomes:
target: source(s)
execution command
Translating the Pipeline into “Recipes” for make
In “make code,” the workflow above - saved in a makefile (a file called makefile, without a file type ending) - becomes:
../../gen/data-preparation/temp/cleaned_data1.csv ../../gen/data-preparation/temp/cleaned_data2.csv ../../gen/data-preparation/temp/cleaned_data3.csv: ../../data/dataset1/raw_data1.xlsx ../../data/dataset2/raw_data2.xlsx ../../data/dataset3/raw_data3.xlsx python to_csv.py
python to_csv.py
../../gen/data-preparation/temp/merged.csv: ../../gen/data-preparation/temp/cleaned_data1.csv ../../gen/data-preparation/temp/cleaned_data2.csv ../../gen/data-preparation/temp/cleaned_data3.csv merge.R
R --vanilla --args "" < "merge.R"
 Tip
TipPay attention to the subdirectory structure used here: the rules refer to files in different folders (src, gen, data, etc.), which are explained earlier in this guide.
Running make
Building your pipeline / running make
You run the entire workflow by typing make in the directory where the makefile is located.
Preview your pipeline, “dry run”
If you type make -n, you are entering a sort-of “preview” mode: make
will provide you a list of commands it would execute - but it does not
actually execute them. Great to preview how a workflow would be executed!
Consider Source Code or Targets as Up-to-Date
By default, make runs each step in a workflow that needs to be
updated. However, sometimes you wish to only rebuild some but not all
parts of your project. For example, consider the case where you have only
added some comments to some R scripts, but re-running that part of the project
would not change any of the resulting output files (e.g., let’s say a dataset).
There are two ways in which you can “skip” the re-builds, depending on whether you want to consider file(s), or targets as up-to-date. Recall that targets are higher-order recipes, whereas files are, well, merely files.
Considering a target as up-to-date:
Pass the parameter -t targetname to make, and press enter. For example,
make -t targetname
The targetname is now “up-to-date”. When you then run make,
it will only run those files necessary to build the remainder of the workflow.
Considering source code as up-to-date:
Pass the parameter -o filename1 filename2 to make.
In other words, filename1 and filename2 will be considered “infinitely old”,
and when rebuilding, that part of the project will not be executed.
 Warning
WarningOf course, using -t and -o should only be used for prototyping your
code. When you’re done editing (e.g., at the end of the day), make
your temporary and output files, and re-run make
to see whether everything works (and reproduces).
Advanced use cases
This book by O’Reilly Media explains all the bells and whistles about using make. Definitely recommended!
Miscellaneous
Why is make useful?
-
You may have a script that takes a very long time to build a dataset (let’s say a couple of hours), and another script that runs an analysis on it. You only would like to produce a new dataset if actually code to make that dataset has changed. Using
make, your computer will figure out what code to execute to get you your final analysis. -
You may want to run a robustness check on a larger sample, using a virtual computer you have rented in the cloud. To run your analysis, you would have to spend hours of executing script after script to make sure the project runs the way you want. Using
make, you can simply ship your entire code off to the cluster, change the sample size, and wait for the job to be done.
Are there alternatives to make?
Other build tools
There are dozens of build tools in the market, many of which are open source. For more information, please check Awesome Pipeline and Awesome Workflow.
-
Bazel: Google’s next generation build system
Readme.txt
Don’t have time to set up a reproducible workflow using make?
A readme.txt - or, in other words, a plain text file with some documentation - is great alternative.
They are very useful to provide an overview about what the project is
about, and many researchers also use them to explain in which order to run scripts. But then again,
you would have to execute that code manually.
make.bat - A bash Script
What you see with other researchers is that they put the running instructions into a bash script,
for example a .bat file on Windows. Such a file is helpful because it makes the order of
execution explicit. The downside is that such a file will always build everything - even those
targets that are already up-to-date. Especially in data- and computation-intensive
projects, though, you would exactly want to avoid that to make quick progress.
To sum up, we prefer make over a readme.txt or a make.bat. But better have one of those than no documentation at all.
 Summary
SummaryWhat is make, and how can we use it to automate pipelines?
With make, we:
-
explicitly document the workflow, making communication with colleagues (and especially our future selves) more efficient,
-
can reproduce the entire workflow with one command,
-
keep track of complicated file dependencies, and
-
are kept from repeating typos or mistakes - if we stick to using
makeeverytime we want to run our project, then we must correct each mistake before we can continue.