


Overview
In this building block, you will learn how to download files directly from URLs using R and Python. By doing this, it will be much simpler for you to re-run your project's workflow in the event of data updates.
Downloading data through R and Python
The functions download_data defined below allow you to download files from R and Python from the corresponding download URLs. For the functions to work, you should provide the desired filename to assign to the downloaded data, the storage path, and the download URL itself.

download_data <- function(url, filename, filepath) {
# Create directory if it doesn't exist
if (!dir.exists(filepath)) {
dir.create(filepath)
}
# Download file
download.file(url = url, destfile = paste0(filepath, "/", filename))
}
download_data(url = "DOWNLOAD_URL", filename = "YOUR_FILENAME.csv", filepath = "STORAGE/PATH/")
import os
import requests
def download_data(url, filename, filepath):
# Create new directory if it doesn't exist
if not os.path.exists(filepath):
os.makedirs(filepath)
# Download the file
response = requests.get(url)
with open(os.path.join(filepath, filename), 'wb') as f:
f.write(response.content)
download_data(url = "DOWNLOAD_URL", filename = "YOUR_FILENAME.csv", filepath = "STORAGE/PATH/")
Advanced Use Cases
Running the download code from the terminal
To integrate data downloading into your data pipeline, It is useful to save the download code in a dedicated file. Then, you can easily execute it from the terminal (e.g. as part of a make workflow) to download your data. In the case of R, that can be done by executing the following in your command line:
R --vanilla < DOWNLOAD_SCRIPT.R
If instead, you wish to do the same for Python, the equivalente command would be:
python DOWNLOAD_SCRIPT.py
 Tip
TipKeep in mind that the filepath is dependent on the location from where your R script is called. The use of absolute directory names (e.g., c:/research/project) should be avoided so that the code remains portable to other computers and work environments.
Open (rather than download) data
The code snippets above download the data from the web, but do not yet open it. If the target data is in tabular format (i.e., has rows and columns), you could directly load it into R using the read.table function. Analogously, the same can be done in Python employing the read_csv function of the package pandas.
data <- read.table("DOWNLOAD_URL", sep = ',', header = TRUE)
import pandas
data = pandas.read_csv("DOWNLOAD_URL")
Downloading and uploading data from Google Drive
The Google Drive API offers a way to programmatically download and upload files through, for example, a Python script. Keep in mind that this only works for files stored in your own Google Drive account (i.e., your own files and those shared with you).
Google Cloud Platform
Like Amazon and Microsoft, Google offers cloud services (e.g., databases and compute resources) that you can configure through an online console. In Google Cloud Platform you can also enable services like the Google Drive API, which we'll make use of here. Follow the steps below to get started.
TipGoogle offers a 90-day trial with a €300 credit to use, but you can keep on using the Drive API after that because it's free to use. In other words, you can follow along without filling out any credit or debit card details.
-
Sign in to Google Cloud Platform and agree with the terms of use (if necessary).
-
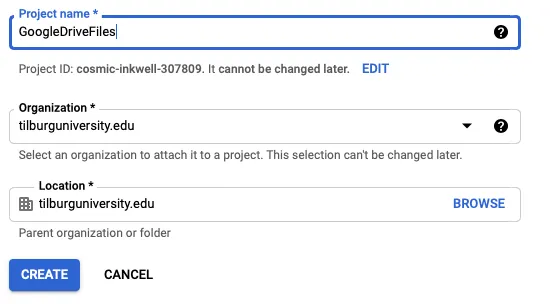
Click on "Create New Project", give it a project name (e.g.,
GoogleDriveFiles), and click on "Create".
- Next, we need to set up a so-called OAuth2 client account which is a widely used protocol for authentication and authorization of API services.
- From the navigation menu in the left top click on "APIs & Services" > "OAuth consent screen".
- Set the user type to "External" and click on "Create".
- Give your app a name (can be anything) and fill out a support and developer email addresses. Click "Save and continue" (it may sometimes throw an app error, then just try again!).
- Click "Save and continue" twice and then "Back to dashboard".
- Click on "Publish app" and "Confirm".
- In the left sidebar, click on "Credentials" and then "Create Credentials" > "OAuth client ID". Then, from "application type" menu "Desktop app" and click on "Create". It will show you your client ID and client secret in a pop-up screen. Rather than copying them from here, we will download a JSON file that contains our credentials. Click on "OK" and then on the download symbol:

* Rename the file to `client_secret.json` and store it in the same folder as the scripts you'll use to download and upload the files.
-
By default, the Google Drive API is not activated, look for it in search bar and click on "Enable".
-
Download google_drive.py from this link. Then click on "Raw" > "Save as" and store it in the same directory as the client secret.
-
Run the following command to install the Google Client library:
pip install google-api-python-client google-auth-httplib2 google-auth-oauthlib
- Create a new Python script (or Jupyter Notebook) and run the following code to set up an API connection.
API Connection
import io, os
from googleapiclient.http import MediaIoBaseDownload
from googleapiclient.http import MediaFileUpload
from google_drive import create_service
CLIENT_SECRET_FILE = 'client_secret.json'
API_NAME = 'drive'
API_VERSION = 'v3'
SCOPES = ['https://www.googleapis.com/auth/drive']
service = create_service(CLIENT_SECRET_FILE, API_NAME, API_VERSION, SCOPES)
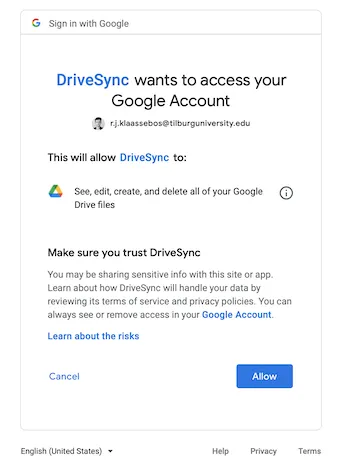
The first time a new window may pop up that asks you to authenticate yourself with your Google account. Select the same account that you used to sign in to the Google Cloud platform. Click on "Allow".
Depending on whether you'd like to download or upload a file, follow one of two approaches:
Download a file
request = service.files().get_media(fileId="<FILE_ID>")
fh = io.BytesIO()
downloader = MediaIoBaseDownload(fd=fh, request=request)
done = False
while not done:
status, done = downloader.next_chunck()
print("Download progress {0}".format(status.progress() * 100))
fh.seek(0)
with open("<FILE_NAME.extension>", 'wb') as f:
f.write(fh.read())
f.close()
# install `googledrive` library if it is not installed already
install.packages("googledrive")
#load `googledrive` library
library(googledrive)
data_id <-"<data_id>"
drive_download(as_id(data_id), path = “<FILE_NAME.extension>”, overwrite = TRUE)
df <- read.extension(“<FILE_NAME.extension>”)
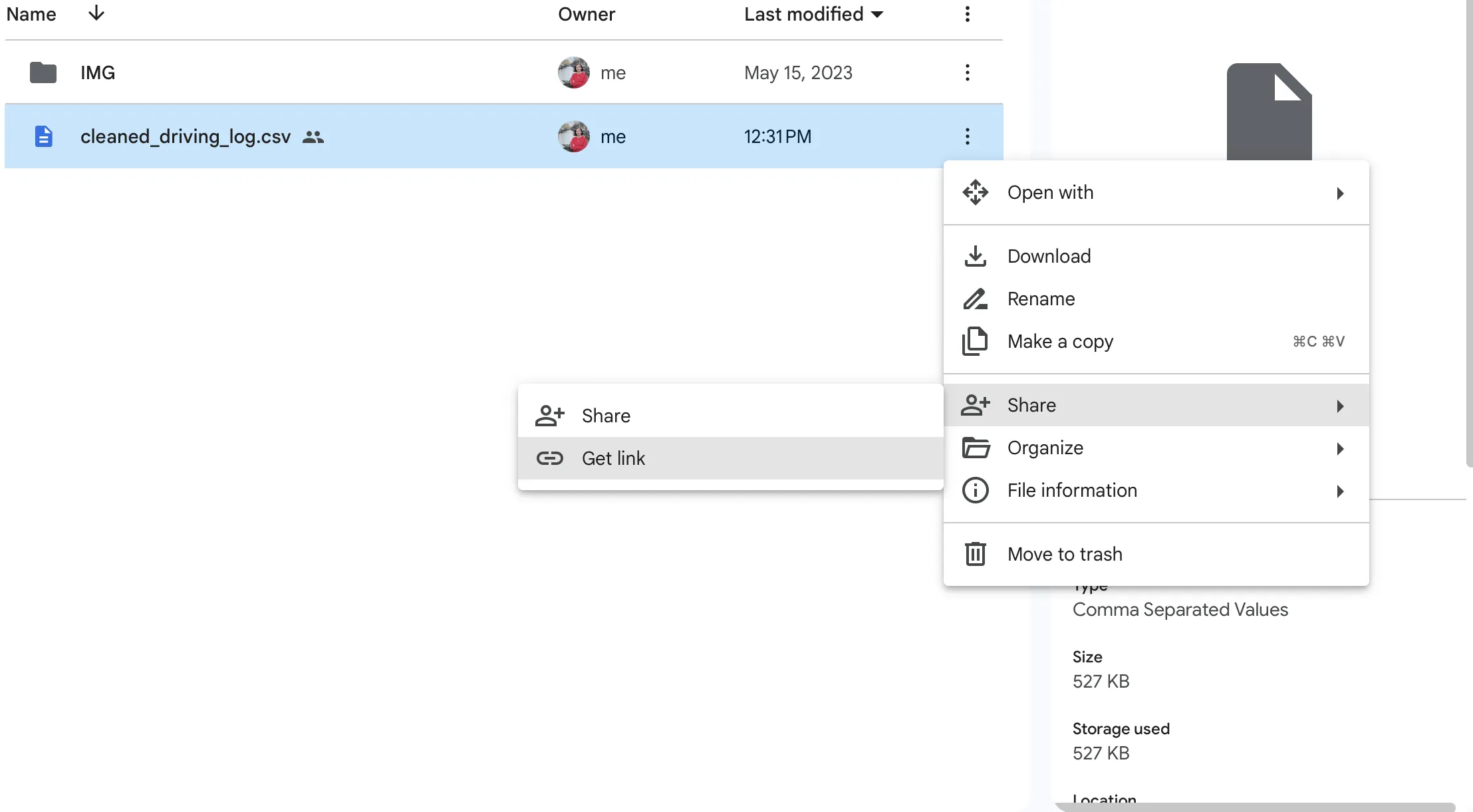
- You can find the
<FILE_ID>/<data_id>by navigating towards the file in your browser and clicking on "share", then "Get link". The URL contains the file ID(data_id) you need. For example, the file ID ofhttps://drive.google.com/file/d/XXXXXX/viewisXXXXXX.
-
R may ask "Is it OK to cache OAuth access credentials in the folder
path/gargle/gargle/Cache between R sessions?".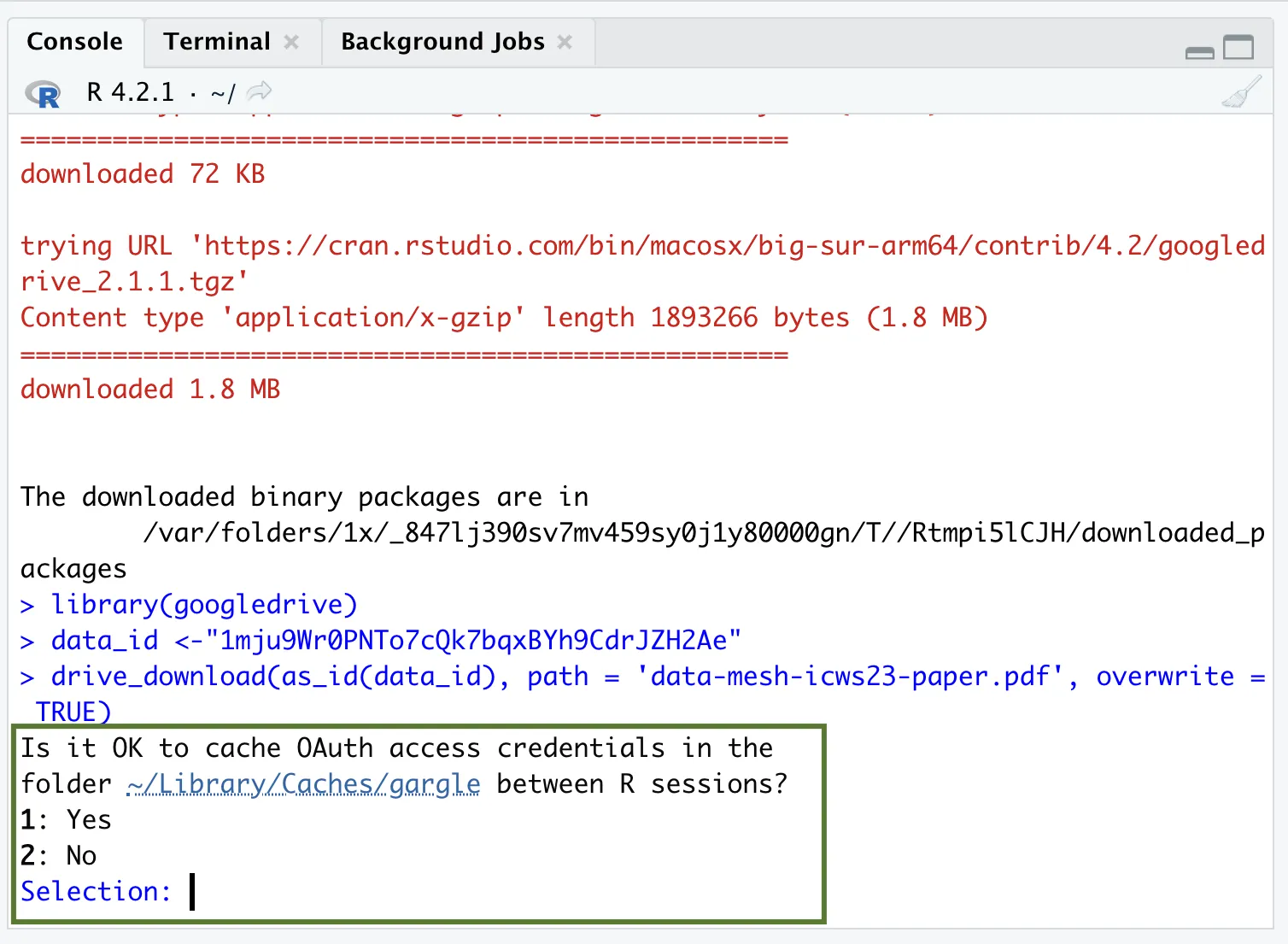
- Type in 1 in the R console to accept. A new window will pop up that asks you to authenticate yourself with your Google account. Click on “Allow” and then "continue".
-
Larger files may be split up in separate chunks. The progress will be printed on the console.
-
To save the file in a subdirectory, you can use the following syntax:
os.path.join("./<SUBDIRECTORY>", "<FILE_NAME.extension>")within theopen()function.
Upload a file
file_metadata = {
## provide the file name on your local machine
"name": "<FILE_NAME.extension>",
## folder Id on your google drive
"parents": ["<FOLDER_ID>"]
}
media = MediaFileUpload("<FILE_NAME.extension>", mimetype="<MIME_TYPE>")
service.files().create(
body = file_metadata,
media_body = media,
fields='id'
).execute()
-
You can get the
in a similar way to how you obtain the . Navigate towards the folder where you'd like to save the file and look for the identifier within the "Shared link". For example, the folder id of https://drive.google.com/drive/folders/XXXXXXXXX?usp=share_linkisXXXXXXXXX. -
The
MediaFileUpload()function assumes that the file supposed to be uploaded is stored in the current directory. If not, add the subdirectory in which the file is stored to the path. -
<MIME_TYPE>informs Google Drive about the type of file to be uploaded (e.g.,csv,jpg,txt). You can find a list of common MIME types over here. For example, the MIME type for a CSV file istext/csv, and for a PDF file, it isapplication/pdf. Summary
Summary- Downloading files: we explored how to download files from URLs and store them locally using both
RandPython, as well as how to download files directly from the terminal. - Opening files: Learn how to access data directly via URL using
RandPython - Downloading and uploading data from google drive
- using google drive API to handle downloads and uploads data.
- Implementing
PythonandRscripts to download data from Google Drive and upload it back to Google Drive from a local machine.
- Downloading files: we explored how to download files from URLs and store them locally using both