


Overview
The ability to process and analyze text data is increasingly important in the era of big data. From social media analytics to customer feedback analysis, the insights gained from text data can inform decision-making and reveal trends. However, raw text data is often messy and unstructured. Preprocessing this data into a clean format is essential for effective analysis.
This tutorial introduces the fundamental techniques of text preprocessing in Python, utilizing the pandas library for data manipulation, spaCy for tokenization and lemmatization, and matplotlib for data visualization. By the end of this guide, you'll be equipped with some fundamental skills to prepare text data for a Natural Language Processing (NLP) project.
 Tip
TipAre you an R user? Then check out our Text Pre-processing in R topic!
Introduction to text preprocessing
When building machine learning models, we typically work with numeric features as models only understand numerical data. However, there are cases where our features are in categorical text format. In such situations, we need to preprocess and encode these features into numerical format, often referred to as vectors, using techniques like Label Encoding or One Hot Encoding.
The main challenge arises when our entire feature set is in text format, such as product reviews, tweets, or comments. How do we train our machine learning model with text data? As we know, machine learning algorithms only work with numeric inputs.
Natural Language Processing
NLP is a branch of Artificial Intelligence (AI) that enables computers to understand, interpret, manipulate, and respond to human language. In simple terms, NLP allows computers to comprehend human language.
In order to effectively preprocess text data, it is important to understand key techniques such as tokenization, stemming, and lemmatization. These techniques play a crucial role in breaking down text into smaller units, reducing words to their base form, and producing valid words respectively.
Python provides several libraries for Natural Language Processing (NLP), including NLTK and spaCy. Both are widely used in the NLP community and offer powerful features for text preprocessing and analysis in Python.
-
NLTK(Natural Language Toolkit) is a popular library that offers a wide range of tools and resources for tasks such as tokenization, stemming, lemmatization, and more. -
spaCyis a modern and efficient library that provides advanced NLP capabilities, including tokenization, part-of-speech tagging, named entity recognition, and dependency parsing.
Let's dive deeper into these NLP concepts.
Tokenization
Tokenization is the process of breaking down a text into smaller units called tokens. These tokens can be words, sentences, or even characters, depending on the level of granularity required. Tokenization is an essential step in text preprocessing as it forms the basis for further analysis and manipulation of text data.
- Example:

import spacy
# Load the spaCy model
nlp = spacy.load("en_core_web_sm")
# Sample text
text = "Here's an example of tokenization: breaking down text into individual words!"
# Tokenize the text
doc = nlp(text)
# Extract tokens
tokens = [token.text for token in doc]
print(tokens)
The output will be a list of tokens: ["Here", "'s", "an", "example", "of", "tokenization", ":", "breaking", "down", "text", "into", "individual", "words", "!"]. Notice how punctuation and spaces are treated as separate tokens, which is typical in word tokenization.
Stemming
Stemming is a technique used to reduce words to their base or root form, known as the stem. It involves removing suffixes and prefixes from words to obtain the core meaning. Stemming helps in reducing the dimensionality of text data and can be useful in tasks such as information retrieval and text classification.
- Example:
from nltk.stem import PorterStemmer
from nltk.tokenize import word_tokenize
# Initialize the stemmer
stemmer = PorterStemmer()
# Sample text
text = "The boys are playing football. One boy is injured."
# Tokenize the text
tokens = word_tokenize(text)
# Stem each token
stemmed_tokens = [stemmer.stem(token) for token in tokens]
print(stemmed_tokens)
The output might look like ['The', 'boy', 'are', 'play', 'footbal', '.', 'One', 'boy', 'is', 'injur', '.'], demonstrating how stemming simplifies words to their roots, albeit not always in a grammatically correct form.
Lemmatization
Lemmatization, unlike stemming, reduces words to their base or dictionary form, known as the lemma. It involves a more sophisticated analysis of a word's morphology to arrive at its simplest form, which ensures that the result is a valid word.
- Example:
import spacy
# Load the spaCy model
nlp = spacy.load("en_core_web_sm")
# Sample text
text = "The boys are playing football. One boy is injured."
# Tokenize and lemmatize the text
doc = nlp(text)
# Extract lemmatized tokens
lemmatized_tokens = [token.lemma_ for token in doc]
print(lemmatized_tokens)
The output will be: ['the', 'boy', 'be', 'play', 'football', '.', 'one', 'boy', 'be', 'injure', '.']. Here, verbs like "are" and "is" are lemmatized to "be", and "injured" to "injure", ensuring the result is grammatically viable.

Practical Example
In this tutorial, we will explore the process of loading, cleaning, and preprocessing text data from a dataset containing subReddit descriptions. SubReddits are specific communities within the larger Reddit platform, focusing on various topics such as machine learning or personal finance.
Loading data
First, we'll use the pandas library to load our dataset:
import pandas as pd
# Example path might need to be changed to your specific file location
file_path = 'subreddit_descriptions.csv'
# Load the dataset
df = pd.read_csv(file_path)
# Preview the first few rows of the dataframe
print(df.head())
Cleaning the data
Before diving into preprocessing, it's crucial to clean our data. This step often involves removing or filling missing values, eliminating duplicate entries, and possibly filtering out irrelevant columns.
# Drop duplicate descriptions
df.drop_duplicates(subset='description', inplace=True)
# Drop rows with missing descriptions
df.dropna(subset=['description'], inplace=True)
# Reset the index after the drop operations
df.reset_index(drop=True, inplace=True)
print("Data after cleaning:")
print(df.head())
Visualizing Data Before Preprocessing
With the data loaded and cleaned, we can get a visual sense of the text we're working with. This initial look will help identify common terms that could skew our analysis if left unchecked.
Word Cloud
Creating a word cloud from the raw text data gives us a visual feast of the most prominent words. In this colorful representation, it's easy to spot Reddit-centric language and other non-informative stopwords that we'll want to remove to refine our analysis.
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# Combine all descriptions into a single string
text_combined = ' '.join(df['description'])
# Generate and display the word cloud
wordcloud = WordCloud(max_words=1000, background_color='white').generate(text_combined)
plt.figure(figsize=(8, 6))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()

Top Terms
The bar plot provides a clear visualization of the most frequent terms in our dataset. It is evident that terms like "subreddit" and "community" are highly prevalent, along with common stopwords such as "and" or "the":
from collections import Counter
# Split the combined text into words and count them
words = text_combined.split()
word_counts = Counter(words)
# Get the top 50 most common words
top_50_words = word_counts.most_common(50)
words, frequencies = zip(*top_50_words)
# Create the bar plot
plt.figure(figsize=(10, 8))
plt.barh(range(len(top_50_words)), frequencies, tick_label=words)
plt.gca().invert_yaxis() # Invert y-axis to have the highest count at the top
plt.xlabel('Frequency')
plt.title('Top 50 Terms in Descriptions')
plt.show()
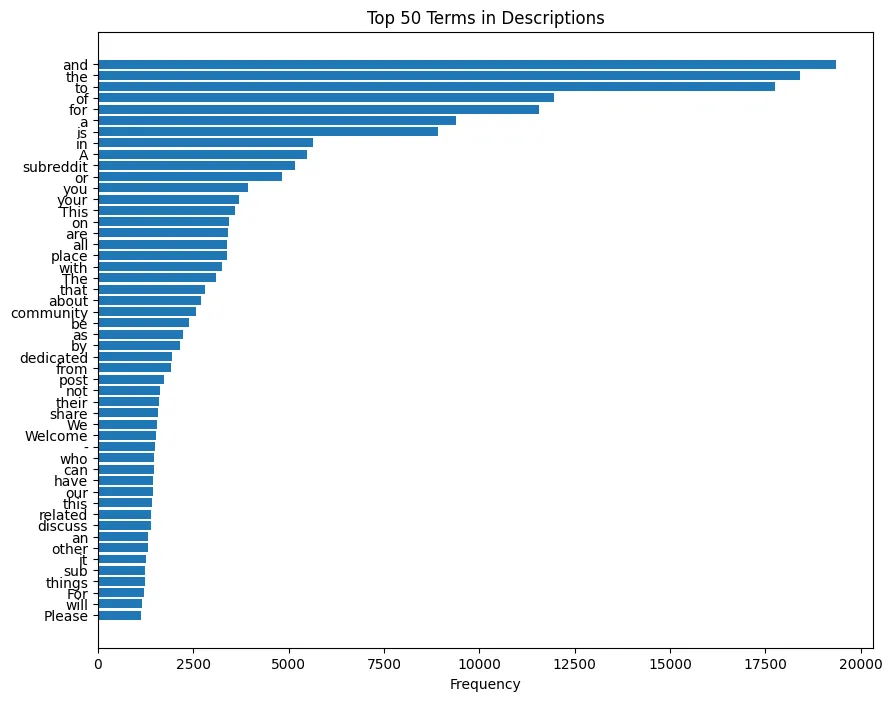
The visuals underscore the necessity of preprocessing: we need to filter out the noise to uncover the true signal in our text data. By removing some Reddit-specific jargon (subreddit, community, etc.) and stopwords (and, the, for, etc.), tokenizing, and lemmatizing the text, we can focus our analysis on words that carry the most meaning.
Text Preprocessing
The preprocessing function defined below performs the following actions to clean and standardize the text data:
- Standardizes Capitalization: Converts all text to lowercase to ensure uniformity.
- Removes Noise: Strips out URLs and special characters, retaining only significant textual elements.
- Simplifies Text: Reduces repetition of characters to prevent distortion of word frequency and meaning.
- Processes Text: Utilizes
spaCyto tokenize and lemmatize the text, filtering out stopwords and punctuation for cleaner tokens. - Corrects Spelling: Applies a spell-checking process to tokens that appear misspelled due to character repetition.
import spacy
import re
from spellchecker import SpellChecker
# Load the spaCy model
nlp = spacy.load('en_core_web_sm')
# Define the set of custom stop words specific to Reddit
reddit_stop_words = {'subreddit', 'community', 'discussion', 'share', 'welcome'}
for word in reddit_stop_words:
# Add each custom stop word to spaCy's vocabulary so they will be recognized as stop words
nlp.vocab[word].is_stop = True
# Define the text preprocessing function
def preprocess_text(text):
# Convert to lowercase to normalize the case
text = text.lower()
# Remove URLs
text = re.sub(r'https?://\S+|www\.\S+', '', text)
# Remove special characters, keeping only words and basic punctuation
text = re.sub(r'[^a-zA-Z0-9\s,.?!]', '', text)
# Reduce excessive character repetition to a maximum of two occurrences
text = re.sub(r'(.)\1{2,}', r'\1\1', text)
# Tokenize and lemmatize the text, removing stop words, punctuation, and short words
doc = nlp(text)
tokens = [token.lemma_ for token in doc if not token.is_stop and not token.is_punct and len(token.text) > 2]
# Correct tokens with repeated characters using a spell checker
spell = SpellChecker()
corrected_tokens = [spell.correction(token) if re.search(r'(.)\1', token) else token for token in tokens]
# Join the tokens back into a single string, removing any potential None values
return " ".join(token for token in corrected_tokens if token is not None and token != '')
# Apply the preprocessing function to the 'description' column
df['processed_description'] = df['description'].apply(preprocess_text)
With this code, each description in the DataFrame will be processed and stored in a new column processed_description, which will contain the cleaned and standardized text ready for further NLP tasks or machine learning modeling.
Visualize Data After Preprocessing
Let's test our preprocessing function with few comment examples before and after applying the preprocessing steps:
# Example usage with sample comments
sample_texts = [
"Here's an example **Çcomment1: I LOVE TILBURG UNIVERSITY and machine learninggg!! 😊 http://example.com",
"OMG, I love New Yorkkkk City so much!! 🍎🚕",
"This is a great Subreddit community! I enjoy reading what you say"
]
# Print the original and processed texts
for sample_text in sample_texts:
processed_text = preprocess_text(sample_text)
print("Original text:", sample_text)
print("Processed text:", processed_text)
print()

We can appreciate our function is doing a good job at cleaning up the sample comments, retaining the most relevant and insightful terms. But let's look at the results on our whole dataset using a word cloud once again:
# Combine all preprocessed descriptions into a single string
preprocessed_text_combined = ' '.join(df['processed_description'])
# Generate and display the word cloud for preprocessed text
wordcloud = WordCloud(max_words=1000, background_color='white').generate(preprocessed_text_combined)
plt.figure(figsize=(8, 6))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()

After applying text preprocessing techniques, we can observe a shift in the most common terms. Instead of generic words, we now see more specific terms related to entertainment (e.g., game, meme), personal discussions (e.g., relate, people), and group identity (e.g., fan, sub), among others. This refined set of words provides valuable insights for various NLP tasks, such as sentiment analysis, topic modeling, and community analysis.
By cleaning and standardizing the text, we create a foundation for advanced algorithms like BERT, which can understand the context of these terms, or methods like TF-IDF, which can highlight the importance of each term in the corpus.
These techniques enable us to gain meaningful insights and interpretations from the data. If you're interested in learning more about it, stay tuned for our Machine Learning section!