


Overview
The estimatr package provides a range of commonly-used linear estimators that allow for easily computation of heteroscedasticity robust, cluster-robust, and other design appropriate standard error estimates
In this building block we will walk you through the process of estimating regression coefficients using the most commonly used functions in estimatr: lm_robust() and iv_robust(). We analyse data from the wage2 data set which is an in-built data set in R, provided by the wooldridge package.
We are interested in examining how the education level of employees relates to their wages and to do so we use the following regression model:
$Wage_{i} = \beta_{0} + \beta_{1} Educ_{i} + \mu$
| Variable | Description |
|---|---|
wage | monthly earnings |
educ | years of education |
Load packages

install.packages("estimatr")
install.packages("wooldridge")
library(estimatr)
library(wooldridge)
data(wage2)
Model Estimation
Before diving into the estimatr package, let's first use the built-in lm() function to estimate our linear model,
$Wage_{i} = \beta_{0} + \beta_{1} Educ_{i} + \mu$
reg <- lm(data=wage2, wage~educ)
summary(reg)
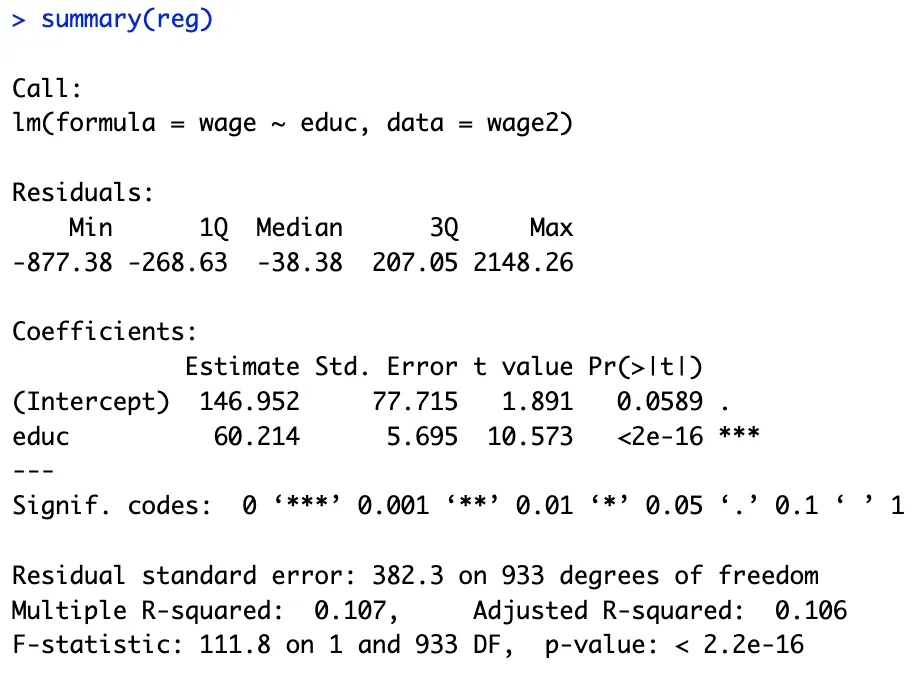
The resulting regression estimates are prone to inefficiency because lm() function is specifically designed to fit linear models that assumes homoscedasticity, which may not always hold true in a specific application.
estimatr provides an alternative that offers quick and easy ways to adjust standard errors, allowing for robust and clustered standard errors.
Heteroscedasticity Robust Estimates with lm_robust()
The lm_robust() function is used to get the robust standard errors from a linear regression model.
Let's re-estimate the model using robust standard errors.
lm_robust(data=wage2, wage~educ, se_type = "HC2")

The se_type argument refers to the sort of standard error that one seeks for in the model. If nothing is specified, HC2 is used as a default option which includes a small sample correction to improve the accuracy of the standard errors.
Upon re-estimating the regression model with the HC2 option for heteroscedasticity-robust standard errors, we notice that the standard errors differ from the previous estimation. This discrepancy indicates that the model now accounts for the presence of heteroscedasticity, resulting in more efficient and reliable standard errors.
However, there are different se_types that are appropriate for different assumptions about the error terms and sample size, and one can choose accordingly from them:
classical: This option uses the classical or ordinary least squares (OLS) estimator to calculate standard errors. It assumes that the error terms are homoscedastic and uncorrelated with the independent variables.
lm_robust(data=wage2, wage~educ, se_type = "classical")

We can observe that this option gives us exactly the same result as we obtained with the lm() function.
-
HC0: This option uses the heteroscedasticity-consistent estimator to calculate standard errors. It allows for heteroscedasticity in the error terms, but does not correct for small sample bias. -
HC1: This option uses the HC1 estimator to calculate standard errors. It is similar to the HC0 estimator, but includes a different sample correction than the HC2 estimator. -
HC3: This option uses the HC3 estimator to calculate standard errors. It is similar to the HC2 estimator, but includes a more robust small sample correction that is less sensitive to outliers.
Cluster-Robust Standard Errors
Cluster-robust standard errors are designed to allow for correlation between observations within a cluster.
For cluster-robust inference, estimatr provides cluster robust variance estimators: CR0 and CR2(default).
For illustrative purposes let's create an ID variable that will be used as a cluster variable.
install.packages("dplyr") # If not already installed
library(dplyr)
# Creating an ID column using row_number()
wage2 <- wage2 %>%
mutate(ID = row_number())
Now estimate the model with cluster-robust standard errors:
lm_robust(data=wage2, wage~educ, se_type = "CR2", cluster = wage2$ID)
 Tip
TipCheck out the mathematical notes for each of the estimators to better understand the formulas used to compute these standard errors to have a more granular understanding of the different use-cases of the different types.
Estimate with iv_robust()
The iv_robust function is used to estimate Instrumental Variable (IV) regressions with heteroscedasticity robust and cluster robust standard errors.
Suppose IQ is a potential instrument (i.e. it is correlated with education but not with the error term) we can obtain the heteroscedasticity robust standard errors as follows:
iv_robust(data=wage2, wage~educ|IQ, se_type = "HC2")

 Summary
Summary-
estimatris an R package for linear estimators designed for speed and ease-of-use. -
Users can easily recover robust, cluster-robust, and other design-appropriate estimates, and options are provided to obtain standard errors that reflect heteroscedasticity.
-
The package includes among others, linear regression estimators like
lm_robust()andiv_robust(). -
The standard errors can be adjusted using the
se_typeandclusterarguments.